Windows Jump List Parser (jmp)
Introduction
jmp is a command line version of a Windows parser that operates on files that are used to generate Jump Lists. Jump Lists are a new feature, starting with Windows 7. They are similar to shortcuts in that they take one directly to the files or directories that are used on a regular basis. They are different than the normal shortcut in that they are more extensible in what information they display. For example, Internet Explorer will use Jump Lists to display websites frequently visited; Microsoft Office products like Excel, PowerPoint and Word, on the other hand, will show most recently opened documents. Below are two examples: (a) one for Most Frequently Used (MFU) list and (b) one for Most Recently Used (MRU) list.
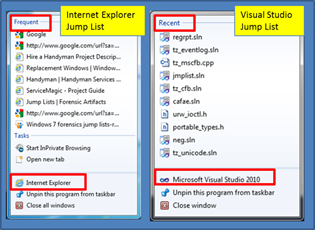
From a user's standpoint, Jump Lists increase one's productivity by providing quick access to the files and tasks associated with one's applications. From a forensics standpoint, Jump Lists are a good indicator of which files were recently opened or which websites were visited frequently.
The Windows operating system derives the Jump List content from two sets of Destination files: (a) the first set is the automaticDestinations type files. These are the ones the operating system creates and maintains. They store information about data file usage. Items are sorted either by Most Recently Used (MRU) or by Most Frequently Used (MFU), depending on the application. (b) The second set is the customDestinations type file. The content contained within, and the tasks specified by this category of file, are maintained by the specific application responsible for that specific Destination file. Suffice to say, both formats rely on the SHLLINK structure to store much of their information.
These two categories of files are located in the following areas on the file system.
- a. %APPDATA%\Microsoft\Windows\Recent\AutomaticDestinations\[AppID].automaticDestinations-ms
- b. %APPDATA%\Microsoft\Windows\Recent\CustomDestinations\[AppID].customDestinations-ms
The variable named %APPDATA% is used to resolve to the C:\Users\<user account>\AppData\Roaming location. From the path, one can see that each user account (or profile) has its own set of Destination files.
The AppID (or application identifier) is used as part of the name in the construction of the Destination filename. This is a 16 character name and is usually based on the process name, but ultimately can be specified by the application.
Automatic Destinations File
The automaticDestinations file consists of a Compound File Binary (CFB) structure as the container for a DestList stream and individual SHLLINK streams. The CFB acts like a file-system within a file, and each SHLLINK structure can be referenced individually via a separate stream. Both the CFB and SHLLINK specifications are individually published by Microsoft as part of their open specifications agreement.
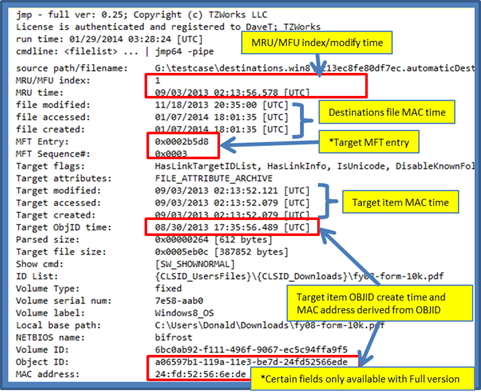
The DestList stream is a collection of MRU/MFU entries whose format is still being investigated, but contains a timestamp, MRU/MFU entry, corresponding SHLLINK stream, NETBIOS name, target file name, object/volume identifiers, and some other unknown information. Combining the DestList information with that of the SHLLINK information, one can have a useful set of forensic artifacts when determining activity on a computer.
Below is a screenshot of the types of information that can be extracted from an automaticDestinations type file:
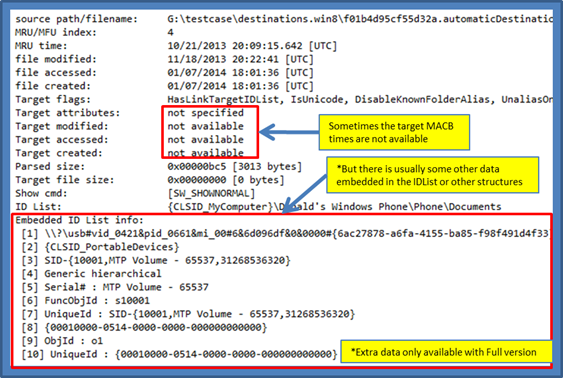
In certain cases, especially with portable devices, some of the more common data may not be present, such as the target's MACB times or MFT entry/sequence number. Fortunately, there is other useful data that can be extracted from the IDList structures. In this example, the device vendor and product identifier can be extracted, as well as, the serial number of the device and the user's security identifier. Below is an example of what a cell phone may look like after connecting to a computer and accessing files on the portable device.
Custom Destinations File
The customDestinations file uses a container structure that is quite different, but simpler, than that of the automaticDestinations file. Aside from the initial header at the beginning of the file, the SHLLINK structures do not follow the orderly grouping (using streams) like that of the Compound File Binary used in the automaticDestinations file. Instead, the SHLLINK structures are packed sequentially.
Secondly, additional custom metadata can be inserted into customDestinations types of files. The contents of this custom data are controlled by the application logging the data. jmp, however, only parses the SHLLINK type metadata from these types of files and does not try to parse any of the unique metadata that may have been placed there by the application.
jmp Tool Parsing vice the lp Tool
When designing the jmp tool, the SHLLINK parsing engine was taken from the TZWorks LNK parsing tool named lp. This engine was wrapped in a compound file stream parsing engine to extract the appropriate streams so the SHLLINK structures could be parsed with assured accuracy.
As an aside, the lp tool also has an option (unlike the jmp tool) to parse SHLLINK structures from raw unstructured data. Using this capability, one can pull out SHLLINK metadata that is buried within an image of a volume (or drive). Furthermore, lp can also parse SHLLINK structures from within a compound file, similar to that of an automaticDestinations file. The lp tool, however, does not associate the automaticDestinations file's MRU/MFU data for each SHLLINK structure parsed, and hence, the reason that the jmp tool was created. More information about what the lp tool can do is discussed on the TZWorks website at lp.
How to Use jmp
While the jmp tool doesn't require one to run with administrator privileges, without doing so will restrict one to only looking at your account's Destinations files or those common to the operating system.
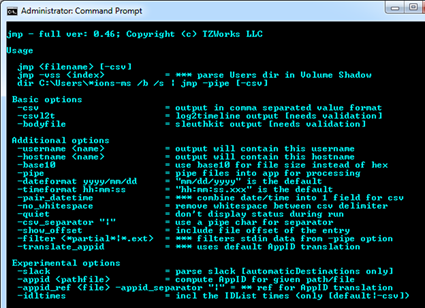
One can display the menu options by typing in the executable name with no parameters. A screen shot of the menu is shown below.
To parse an individual Destinations file, use the following notation:
jmp <Destinations filename> > results.txt
Without specifying one of the format options, the output is rendered in a default, unstructured output. The prior snapshot in the section above is an example of what this output looks like. The information is useful if one is not trying to parse any artifacts into a database. Notice that in the example above, the output is redirected to a text file called 'results.txt'. Since the output that is generated is usually very long (and wide, if using the CSV option), it is recommended that one redirect the output of the command into a file as show above.
The -csv (comma separated value) option will render the output so that all the metadata is rendered with one SHLLINK record per line, where each field is delimited by a comma. The other two output formats are the: (a) -csvl2t and (b) -bodyfile. Each will attempt to conform to either the log2timeline format or the SleuthKit's body-file format, respectively.
While parsing one Destinations file is useful, one will usually want to parse all the Destinations files that are on a system or in a set of directories. One way to do this is to pipe in all the paths/filenames of the Destinations type files one wishes to parse into jmp. To allow jmp to receive data from an input pipe, one needs to invoke the -pipe switch. This will allow jmp to receive a separate path/filename per line as input. To provide this input, one can use the Windows built-in dir command along with some of its own switches to get the desired result. Below is an example:
dir c:\users\*ions-ms /b /s | jmp -pipe -csv > results.csv
The above syntax will process all the Destinations-ms files that are located anywhere in the c:\users directory or subdirectories. This assumes, of course, that one is running with administrator privileges.
When analyzing the CSV output, the automaticDestinations metadata will include the MRU/MFU index, stream and timestamp. The annotated snapshot below has been trimmed to show this information.
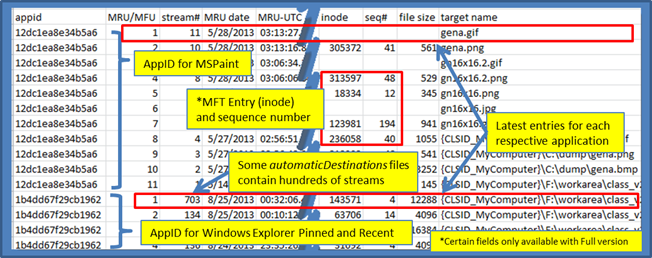
On the left of the output one can see the application identifier. Matching this identifier to a known application can be done by visiting http://www.forensicswiki.org/wiki/List of Jump List IDs, where there are tables of application IDs matched to their respective application.
The MRU/MFU index is a chronological list of entries, where #1 is the latest. Each application ID has its own sequential list. Following the index value is the stream number (or directory name) that holds the data in the compound file. It is not uncommon to find hundreds of streams, where each stream (with a couple exceptions) contains a SHLLINK data structure. The MRU/MFU entry has a unique timestamp that shows when that entry was updated. Finally, some of the entries contain the target's MFT entry (or inode) and sequence number. Combining the MRU/MFU data with that of the SHLLINK metadata and the MFT entry provides a wealth of forensic information to the investigator.
Handling Volume Shadows
To tell jmp to look at a Volume Shadow, one needs to use the -vss <index of volume shadow> option. This then points jmp at the appropriate Volume Shadow snapshot and it starts processing the various user automatic and custom destination files.
For more information
The user's guide can be viewed here
If you would like more information about jmp, contact us via email.
Downloads
| Intel 32-bit Version | Intel 64-bit Version | ARM 64-bit Version | ||||
| Windows: | jmp32.v.0.64.win.zip | jmp64.v.0.64.win.zip | jmp64a.v.0.64.win.zip | md5/sha1 | ||
| Linux: | jmp32.v.0.64.lin.tar.gz | jmp64.v.0.64.lin.tar.gz | jmp64a.v.0.64.lin.tar.gz | md5/sha1 | ||
| Mac OS X: | Not Available | jmp.v.0.64.dmg | jmp.v.0.64.dmg | md5/sha1 | ||
| *32bit apps can run in a 64bit linux distribution if "ia32-libs" (and dependencies) are present. | ||||||