Chromium Cache Parser (ccp)
Introduction
The Chromium Cache Parser (ccp) targets various caches associated with Chromium-based browsers, or browsers that use the cache component of Chromium. This tool addresses parsing caches in these browsers (at least the later versions of these browsers): Google Chrome, Microsoft Edge, Opera, Brave, Vivaldi, and others.
Background
The Chromium cache, is a repository for web data a user has viewed or downloaded. In general, the purpose of the cache is to store data locally, and thus allow the browser quick access for later requests to a previously viewed website. The cache includes: website pages, files, scripts, images and other items that were viewed by a user or data that the browser needed to use. In addition to the raw data that was received from a web server, the cache also contains useful metadata associated with each item. From the point of view of the forensic examiner the cache provides insights to the user's Internet usage, since it contains items such as: the URL of the webpage, number of times the page was fetched from the cache, filename/type/size, last modified time, last fetched time, server time, etc. Having a tool available that can take advantage of this artifact data is necessary to have insights into the user's activity.
The Chromium cache can consist of various types of cache; each cache type can be determined by where it is located in the Chromium directory structure. These various types of cache, include: normal Cache data, CacheStorage type data, Code Cache, and ScriptCache, to name a few. The various cache types can be found in the Chromium project's documentation.
Capabilities
The ccp tool is flexible in that it can target multiple subdirectories of different Chromium-based browser accounts and automatically adjust to the appropriate parsing engine so it can handle various cache formats. If your use-case is to collect artifacts across multiple computers/accounts, and store them in a single repository prior to parsing them, then the ccp tool can parse them all in one go.
To help out keeping the cache metadata (eg. timestamps, URL, http request/response, etc), together with actual cache content (eg. data for the webpage that is displayed) as part of the archive, ccp has the option to combine the metadata results with the raw cache content data by taking advantage of SQLite to store the final results.
If only desiring to extract the cache metadata with pointers to the cache content, one can use the either of the text delimited options CSV or Log2Timeline.
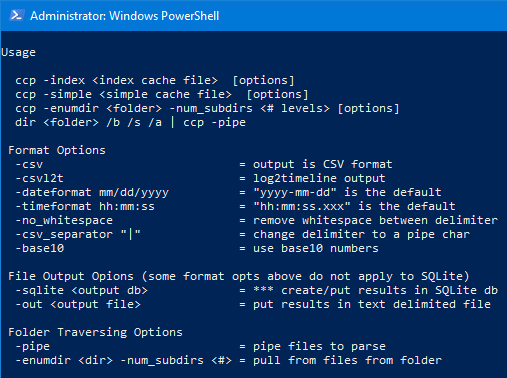
Below is the menu with the various options. The details of the usage is discussed in the user's guide.
Chromium-based Browsers
While the table below is not a complete list, the intent here was to identify some of the more popular browsers that use some form of the Chromium-based cache architecture. These are the ones that were used when testing out the ccp tool. Of those listed, all have browsers operate on at least the following desktop operating systems: Windows, Linux and macOS. Many of these same browsers work on iOS or Android as well.
| Browser | Website |
|---|---|
| Google Chrome | https://www.google.com/chrome |
| Brave | https://brave.com/download |
| Microsoft Edge (newer version) | https://www.microsoft.com/en-us/edge |
| Opera (newer version) | https://www.opera.com/download |
| Vivaldi | https://vivaldi.com/download |
Downloads
| Intel 32-bit Version | Intel 64-bit Version | ARM 64-bit Version | ||||
| Windows: | ccp32.v.0.16.win.zip | ccp64.v.0.16.win.zip | ccp64a.v.0.16.win.zip | md5/sha1 | ||
| Linux: | ccp32.v.0.16.lin.tar.gz | ccp64.v.0.16.lin.tar.gz | ccp64a.v.0.16.lin.tar.gz | md5/sha1 | ||
| Mac OS X: | Not Available | ccp.v.0.16.dmg | ccp.v.0.16.dmg | md5/sha1 | ||
| *32bit apps can run in a 64bit linux distribution if "ia32-libs" (and dependencies) are present. | ||||||